






En el mundo actual existe una cada vez mayor demanda de gestión de la información. No es una demanda nueva, todas las sociedades a lo largo de la historia han tenido esta necesidad. Desde el principio de los tiempos se ha necesitado disponer de herramientas que facilitaran la gestión de los datos ya que, como herramienta, el ser humano al principio sólo disponía de su memoria y cálculo inmediato y, como mucho, de la ayuda de sus dedos.
La escritura fue la herramienta que permitió al ser humano almacenar información y realizar cálculos sobre ella. Además de permitir compartir esa información entre diferentes personas, también posibilitó que los datos se guardaran de manera continua e incluso estuvieran disponibles para las siguientes generaciones. Los problemas actuales con la privacidad ya aparecieron con la propia escritura y así el cifrado de datos es una técnica tan antigua como la propia escritura para conseguir uno de los todavía requisitos fundamentales de la gestión de datos, la seguridad.
Cuanto más se han desarrollado las sociedades, mejores métodos se han desarrollado para gestionar la información y, a la vez, más datos se han necesitado gestionar. Para poder almacenar datos y cada vez más datos, el ser humano ideó nuevas herramientas: archivos, cajones, carpetas y fichas en las que se almacenaban los datos.
Antes de la aparición de las computadoras, el tiempo requerido para manipular estos datos era enorme. Sin embargo el proceso de aprendizaje era relativamente sencillo, ya que se usaban elementos que las personas manejaban desde su infancia.
Por esa razón, la informática se adaptó para que la terminología en el propio ordenador se pareciera a los términos de organización de datos clásicos. Así, en informática se sigue hablado de ficheros, formularios, carpetas, directorios,....
En estos últimos años, la demanda ha crecido a niveles espectaculares debido al acceso multitudinario a Internet y a los enormes flujos de información que generan los usuarios. Cada año la necesidad de almacenar información crece exponencialmente en un frenesí que, por ahora, no parece tener fin.
Desde la aparición de las primeras computadoras, se intentó automatizar la gestión de los datos. El propio nombre Informática hace referencia al hecho de ser una ciencia que trabaja con información. Por ello las bases de datos son una de las aplicaciones más antiguas de la informática.
Tradicionalmente siempre se ha separado el concepto de dato sobre el de información.
Un dato es una propiedad en crudo, es decir, sin contextualizar. Por ejemplo Sánchez y 32 son datos. Desde el punto de vista de la computación, ambos datos se pueden almacenar. Sin embargo, no podemos considerarlos información hasta que no les demos significado. Si decimos que Sánchez es mi primer apellido y que 32 son los grados centígrados de temperatura que hace ahora en la calle, esos datos pasan a ser información.
La información tiene una importancia humana, es interpretable, reconocible, presentable,.. El dato es simplemente el paso previo. Resumiendo: todo dato debe de ser procesado para obtener información, y es la información lo que nos interesa a los seres humanos.
Como veremos más adelante, los datos se convierten en información gracias a los metadatos: datos que sirven para describir otros datos.
Según la RAE, la definición de sistema es “Conjunto de cosas que ordenadamente relacionadas entre sí contribuyen a un determinado objeto” .
La clientela fundamental del profesional de la informática es la empresa, sin distinguir entre la empresa privada y las entidades públicas. Son las empresas las que contratan servicios de tipo informático que, al final, requieren de un sistema que gestione la información de la empresa.
Una empresa está formada por diversos elementos que son comunes: el capital, los recursos humanos, los inmuebles, los servicios que presta, etc. Todos ellos forman el sistema de la empresa.
El sistema completo que forma la empresa, por otra parte, se suele dividir en los siguientes subsistemas:
Hay que hacer notar que cada subsistema se asocia a un departamento concreto de la empresa.
Los sistemas que aglutinan los elementos que intervienen para gestionar la información que manejan los subsistemas empresariales es lo que se conoce como Sistemas de Información. Se suele utilizar las siglas SI o IS (de Information Server) para referirse a este concepto.
Ese término vale también para gestionar la información de cualquier sistema, aunque no sea empresarial, pero la teoría desarrollado al respecto está basada en el sistema empresarial.
Realmente un sistema de información solo incluye aquello que realmente nos interesa gestionar de la empresa. El sistema incluye no solo la información en sí, sino los elementos que permiten realizar esa gestión.
Un sistema de información genérico está formado por los siguientes elementos:
Las empresas necesitan implantar estos sistemas de información debido a la competencia que las obliga a gestionar de la forma más eficiente sus datos para una mayor calidad en la organización de las actividades de los subsistemas empresariales.
En el caso de una gestión electrónica de la información (lo que actualmente se considera un sistema de información electrónico), los componentes son:
En la evolución de los sistemas de información ha habido dos puntos determinantes, que han formado los dos tipos fundamentales de sistemas de información electrónico.
Este tipo de sistemas hace referencia a la forma que inicialmente se desarrolló en la informática para gestionar ficheros (y que aún se usa). En realidad, es una forma que traducía la manera clásica de gestionar sistemas de información (con sus archivadores, carpetas,…) al mundo electrónico.
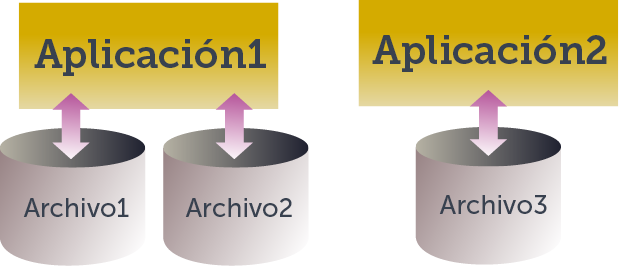
Ilustración 1. Sistema de Información mediante ficheros
La idea es que los datos se almacenan en ficheros y se crean aplicaciones (cuyo código posee la empresa que crea dichas aplicaciones) para acceder a los ficheros. Cada aplicación organiza los datos en los ficheros como le parece mejor y si incorporamos aplicaciones nuevas, estas usarán sus propios ficheros.
Cada aplicación almacena y utiliza sus propios datos de forma un tanto caótica. La ventaja de este sistema (la única ventaja), es que los procesos son independientes por lo que la modificación de uno no afecta al resto. Pero tiene grandes inconvenientes:
Se consideran también sistemas de gestión de ficheros, a los sistemas que utilizan programas ofimáticos (como Word o Excel por ejemplo) para gestionar sus datos. Esta última idea, la utilizan muchas pequeñas empresas para gestionar los datos, debido al presupuesto limitado del que disponen. Gestionar la información de esta forma produce los mismos (si no más) problemas.
Estos serán los sistemas que estudiaremos en estos apuntes.
En este tipo de sistemas, los datos se centralizan en una base de datos común a todas las aplicaciones. Un software llamado Sistema Gestor de Bases de Datos (SGBD) es el que realmente accede a los datos y se encarga de gestionarlos. Las aplicaciones que creen los programadores, no acceden directamente a los datos, de modo que la base de datos es común para todas las aplicaciones.
De esta forma, hay, al menos, dos capas a la hora de acceder a los datos. Las aplicaciones se abstraen sobre la forma de acceder a los datos, dejando ese problema al SGBD. Así se pueden concentrar exclusivamente en la tarea de conseguir una interfaz de acceso a los datos para los usuarios.
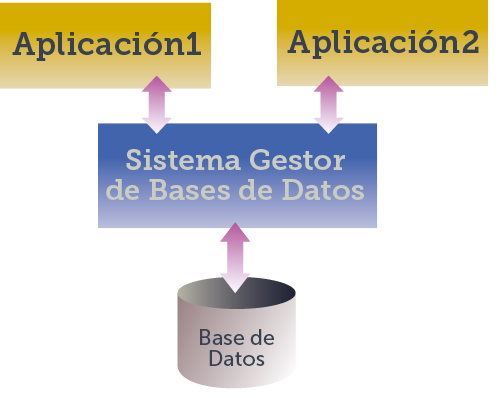
Ilustración 2. Sistemas de información orientados a datos
Cuando una aplicación modifica un dato, la modificación será visible inmediatamente para el resto de aplicaciones; ya que todas utilizarán la misma base de datos.
Aunque los SGBD actuales son capaces de realizar numerosos tipos distintos de tareas, los SGBD tienen que realizar tres tipos de funciones para ser considerados válidos. A continuación se describen estas tres funciones.
Permite al diseñador de la base de datos crear las estructuras apropiadas para integrar adecuadamente los datos. Se dice que esta función es la que permite definir las tres estructuras de la base de datos (relacionadas con los tres niveles de abstracción de las mismas).
Más adelante se explican estas tres estructuras, relacionadas con las tres formas (o niveles) fundamentales de ver la base de datos.
Realmente la función de definición lo que hace es gestionar los metadatos. Los metadatos son la estructura de la dispone el sistema de base de datos para documentar cada dato. Los metadatos también son datos que se almacenan en el sistema; pero su finalidad es describir los datos.
Un metadato nos permite para saber a qué información real se refiere cada dato. Por ejemplo: Sánchez, Rodríguez y Crespo son datos. Pero Primer Apellido es un metadato que, si está correctamente creado, nos permite determinar que Sánchez, Rodríguez y Crespo son primeros apellidos.
Dicho de otra forma, sin los metadatos, no podríamos manejar los datos como información relevante. Por ello son fundamentales. Son, de hecho, la base de la creación de las bases de datos. La combinación entre dato y metadato es la que realmente produce la información.
Los metadatos pueden indicar cuestiones complejas. Por ejemplo, que de los Alumnos almacenamos su nif el cual lo forman 9 caracteres. Incluso podremos indicar que en el nif el primer carácter es un número o las letras X, Y y Z; seguidos de 7 números y un carácter en mayúsculas que además cumple una regla concreta y sirve para identificar al alumno.
Por lo tanto, en realidad, la función de definición sirve para crear, eliminar o modificar metadatos.
Resumiendo: con la función de definición podremos:
Un lenguaje conocido como lenguaje de descripción de datos o DDL, es el que permite utilizar la función de definición en los sistemas de bases de datos.
Ejemplos de acciones relacionadas con esta función:
Permite cambiar y consultar los datos de la base de datos. Se realiza mediante un lenguaje de modificación de datos o DML. Mediante este lenguaje se puede:
Actualmente se suele diferenciar la función de consulta de datos, diferenciándola del resto de operaciones de manipulación de datos. Se habla de que la función de consulta se realiza con un lenguaje de consulta de datos o DQL (Data Query Language).
Ejemplos de acciones relacionadas con esta función:
Mediante esta función los administradores poseen mecanismos para proteger los datos. De manera que se permite a cada usuario ver ciertos datos y otros no, o bien usar ciertos recursos concretos de la base de datos y prohibir otros. Es decir, es la función encargada de establecer los permisos de acceso a los elementos que forman parte de la base de datos.
El lenguaje que implementa esta función es el lenguaje de control de datos o DCL.
Ejemplos de acciones relacionadas con esta función:
Un sistema gestor de bases de datos o SGBD (aunque se suele utilizar más a menudo en los libros especializados las siglas DBMS procedentes del inglés, Data Base Management System) es el software que permite a los usuarios procesar, describir, administrar y recuperar los datos almacenados en una base de datos.
En estos sistemas se proporciona un conjunto coordinado de programas, procedimientos y lenguajes que permiten a los distintos usuarios realizar sus tareas habituales con los datos, garantizando además la seguridad de los mismos.
El éxito del SGBD reside en mantener la seguridad e integridad de los datos. Lógicamente tiene que proporcionar herramientas a los distintos usuarios.
Además de las tres funciones principales comentadas anteriormente, hoy en día los SGBD son capaces de realizar numerosas operaciones. Para ello proporcionan numerosas herramientas, muchas de ellas permiten trabajar de una forma más cómoda con las . Las más destacadas son:
En cualquier software siempre hay dos puntos de vista:
Esta separación distingue al usuario o usuaria, del programador o programadora que ha creado la aplicación, y es crucial que sea así. La persona que utiliza el software evita tener que conocer la forma en la que se crean las aplicaciones. Del mismo modo una casa se la puede observar desde el punto de vista del inquilino de la misma o bien de las personas que la construyeron. Los primeros ven la función real de la misma y los constructores nos podrán hablar de los materiales empleados en la casa y del recorrido que tienen las tuberías de agua o los cables eléctricos.
En el caso de las bases de datos hay más niveles, más formas de observar la base de datos y estos niveles son manejados por los distintos usuarios de la base de datos. A a esas distintas perspectivas a las que se les llama: niveles de abstracción.
Estos niveles nos permiten efectivamente abstraernos para observar la base de datos en base a diferentes intereses. Los usuarios podrán entender la base de datos sin conocer los entresijos técnicos y los administradores podrán trabajar con base de datos sin conocer la forma en la que los usuarios realmente añaden los datos.
Los niveles habituales son:
La idea de estos niveles procede de la normalización hecha en el modelo ANSI/X3/SPARC (Véase [a2] estándares y modelo ANSI en la página 39) y sigue estando muy presente en la gestión actual de las bases de datos.
Este modelo dictó que podemos pasar de unos modelos a otros de manera casi automática utilizando un software adecuado. El modelo ANSI llama a ese software procesador de modelos y hoy en día es lo que se conoce como herramientas CASE (Computer Aided for Software Engineering, Asistente Computerizado para Ingeniería del Software). Para cada nivel se realizan esquemas relacionados con ellos. Así hay esquemas externos (varios), esquema conceptual, esquema interno y esquema físico que forman todos los aspectos de la base de datos.
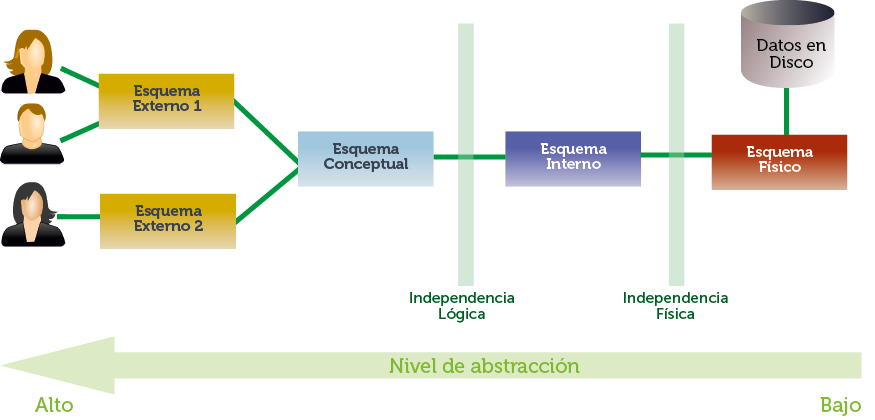
Ilustración 3. Los diferentes esquemas y visiones de una base de datos
En la Ilustración 3 se observa la distancia que poseen los usuarios de la base de datos respecto a la realidad física de la base de datos (representada con el cilindro). La física son los datos en crudo, es decir en formato binario dentro del disco o discos que los contienen. El esquema físico es el que se realiza pensando más en esa realidad y los esquemas externos los que se crean pensando en la visión de los usuarios.
Las dos columnas que aparecen en la imagen reflejan dos fronteras a tener en cuenta:
Intervienen (como ya se ha comentado) muchas personas en el desarrollo y manipulación de una base de datos. Se describen, a continuación, los actores más importantes.
Lógicamente, son los profesionales que definen y preparan la base de datos. Pueden ser:
Son especialistas en gestión de recursos, tanto materiales como humanos.
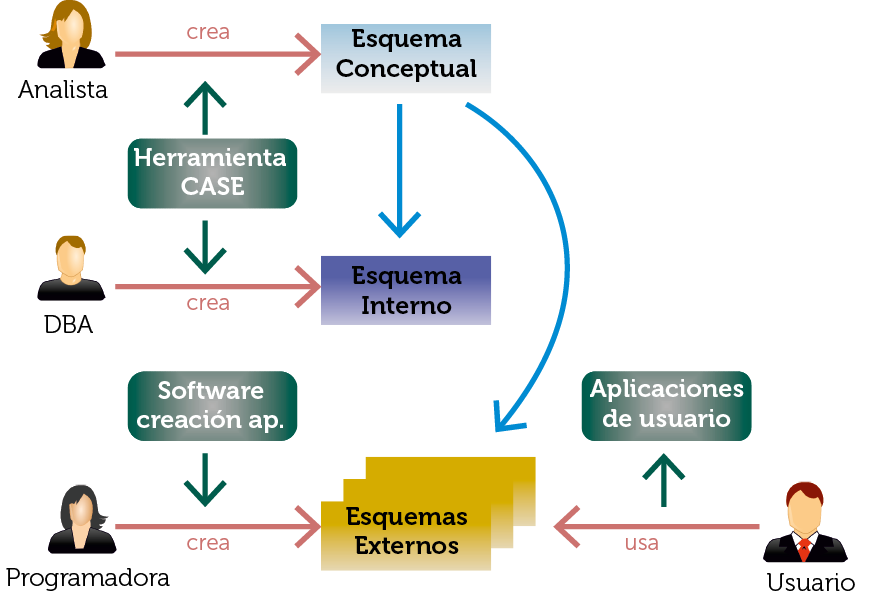
Ilustración 4. Recursos Humanos principales en el proceso de creación y manipulación de una base de datos y su relación cada uno de los esquemas de la base de datos
[1]El analista o diseñador crea el esquema conceptual. En muchas ocasiones, utilizando una herramienta CASE para diseñar el esquema de forma más cómoda.
[2]El administrador de la base de datos (DBA) recoge ese esquema y crea el esquema interno de la base de datos. También se encarga, previamente, de determinar el SGBD idóneo y de configurar el software del SGBD así como de establecer las políticas de copia de seguridad.
[3]Los desarrolladores también recogen el esquema conceptual y utilizan las aplicaciones necesarias para generar los esquemas externos, que realmente se traducirán en programas y aplicaciones, que necesitan los usuarios.
Ocurre con la base de datos ya creada y en funcionamiento.
[1]El usuario realiza una operación sobre la base de datos (una consulta, modifica o añade un dato, etc.)
[2]Las aplicaciones las traducen a su forma conceptual utilizando el diccionario de datos, que posee todos los metadatos necesarios.
[3]El esquema conceptual es traducido por la SGBD a su forma interna, nuevamente con ayuda del Diccionario de Datos.
[4]EL SGBD se comunica con el Sistema Operativo para pedir que acceda al disco (estamos, por lo tanto ya en el nivel físico) y recoja los datos requeridos (siempre con ayuda del Diccionario de Datos).
[5]El Sistema Operativo accede al almacenamiento físico correspondiente y devuelve los datos al SGBD.
[6]El SGBD transforma los datos internos en datos conceptuales y los entrega a la aplicación.
[7]La aplicación muestra los datos habiéndolos traducido a una forma (externa) amigable y apta para ser entregada al usuario que hizo la petición.
El proceso que realiza un SGBD para acceder a los datos está en realidad formado por varias capas que actúan como interface. El usuario nunca accede a los datos directamente. Estas capas son las que consiguen implementar los niveles de abstracción de la base de datos.
Fue el propio organismo ANSI (en su modelo ANSI/X3/SPARC) la que introdujo una mejora de su modelo de bases de datos en 1988 a través de un grupo de trabajo llamado UFTG (User Facilities Task Group, grupo de trabajo para las facilidades de usuario). Este modelo toma como objeto principal al usuario habitual de la base de datos y modela el funcionamiento de la base de datos en una sucesión de capas cuya finalidad es ocultar y proteger la parte interna de las bases de datos.
Desde esta óptica, para llegar a los datos hay que pasar una serie de capas que desde la parte más externa poco a poco van entrando más en la realidad física de la base de datos. Esa estructura se muestra en la Ilustración 5.
Este marco sigue teniendo vigencia actualmente e indica que el acceso a los datos no es instantáneo, que los datos están protegidos de los usuarios que pasan (sin saberlo) por varias capas de proceso antes de que sus peticiones a la base de datos sean atendidas.
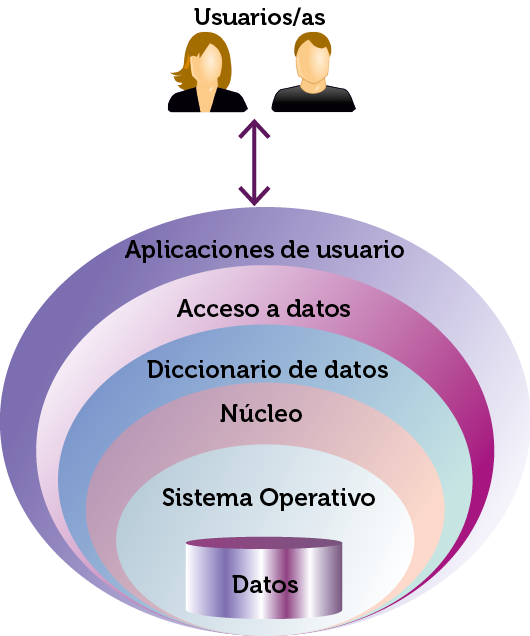
Ilustración 5. Modelo multicapa de acceso a los datos de una base de datos
Se explican las capas en detalle
Es la capa a la que acceden los usuarios. Proporciona el SGBD a los usuarios un acceso más sencillo a los datos. Son, en definitiva, las páginas web y las aplicaciones con las que los usuarios manejan la base de datos. Permite abstraer la realidad de la base de datos a las usuarias y usuarios, mostrando la información de una forma más humana. Forman, por lo tanto, los esquemas externos de la base de datos.
La capa de acceso a datos es la que permite comunicar a las aplicaciones de usuario con el diccionario de datos. Es un software (un driver o controlador, en realidad) que se encarga traducir las peticiones del usuario para que lleguen de forma correcta a la base de datos y ésta pueda responder de forma adecuada.
Sin esta capa, las aplicaciones no podrían llegar al sistema de base de datos. Capas de acceso a datos conocidas por los desarrolladores son las interfaces JDBBC o ODBC que permiten comunicar el código de las aplicaciones con el sistema de base de datos.
Se trata de una estructura interna del SGBD que contiene todos los metadatos. Esta estructura es la almacena los datos de todos los esquemas (externos, interno, físico y conceptual). Se encarga de validar que los metadatos a los que se refieren las peticiones son correctos y que realmente se tiene permiso para ser utilizados.
núcleo
El núcleo de la base de datos es la capa encargada de traducir todas las instrucciones requeridas y prepararlas para su correcta interpretación por parte del sistema. Realiza la traducción física de las peticiones. El núcleo se relaciona con el SGBD en sí, es el cerebro del sistema.
Es una capa externa al software SGBD pero es la única capa que realmente accede a los datos en sí. En realidad los SGBD no pueden guardar o recoger directamente los datos del disco, sino que piden al Sistema Operativo que lo haga, ya que es el que maneja el sistema de discos. Para ello el núcleo debe de indicar de forma concisa y sin ambigüedad donde están realmente situados los datos.
La Ilustración 6 presenta el funcionamiento típico de un SGBD en modo bicapa o cliente servidor que es el que nos interesa. En ella se reproduce la comunicación entre un usuario que desea acceder a los datos y el SGBD:
[1]Los usuarios utilizan una aplicación para acceder a los datos. Estamos en el nivel externo de la base de datos, por lo que la propia aplicación traduce la petición que hizo el usuario de forma sencilla, a una petición entendible por la capa de acceso a los datos.
[2]El proceso cliente es el software de acceso a la base de datos y que está instalado en el lado del cliente. Se encarga simplemente de recoger y enviar la petición (comprobando antes si hay comunicación con el servidor de la base de datos).
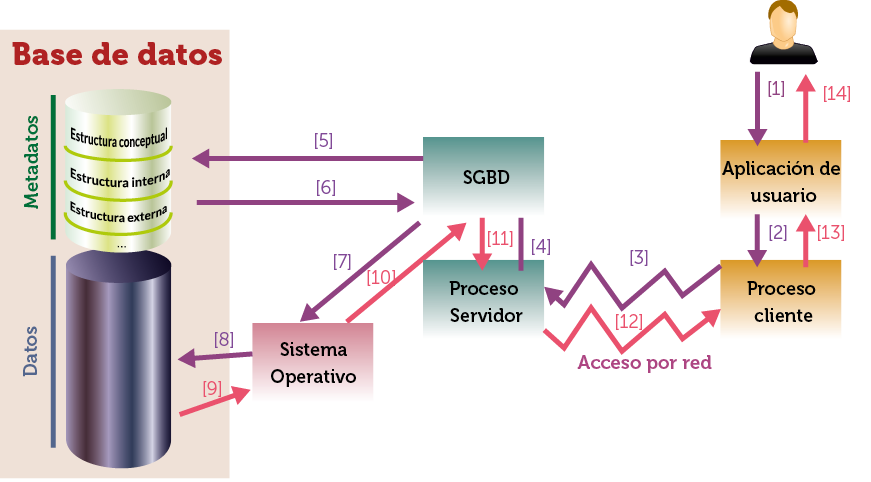
Ilustración 6. Esquema del funcionamiento de un SGBD
[3]A través de la red (normalmente) el proceso cliente se comunica con el proceso servidor, que es el software de comunicación instalado en el lado del servidor. Ambos procesos (cliente y servidor) forman la capa de acceso a los datos y se comunican con ayuda de un interfaz que es el que facilita la traducción de las peticiones y respuestas.
[4]Cuando la petición llega ya al servidor, la recibe el Sistema Gestor de Bases de Datos, el cual requerirá de la ayuda del diccionario de datos.
[5]El SGBD, comprobando el diccionario de datos, comprueba si la petición es correcta.
[6]El SGBD también utiliza el diccionario de datos (si la petición es correcta) para saber con exactitud en qué archivos y en qué parte dentro de ellos, se encuentran los datos requeridos
[7]Con la información sobre dónde están los datos, el SGBD hace una petición al Sistema Operativo, que es el que tiene capacidad realmente de acceder a los archivos de datos. Por ello la petición del SGBD se traduce al formato utilizado por el Sistema Operativo.El Sistema Operativo accede a los datos.
[8]El Sistema Operativo recibe los datos.
[9]Se entregan los datos al Sistema Gestor de Bases de Datos o, si ha habido un error al acceder a los datos, se indica el error ocurrido.
[10]El SGBD traduce los datos a una forma más conceptual (más entendible por el usuario) y se los entrega al proceso servidor.
[11]Los datos se entregan al proceso cliente.
[12]Los datos llegan a la aplicación.
[13]La aplicación de usuario traduce los datos recibidos en información presentada de la forma más conveniente para el usuario.
Se trata de Sistemas Gestores instalados en una máquina desde la que se conectan los propios usuarios y administradores. Es decir, todo el sistema está en una sola máquina.

Ilustración 7. Sistema monocapa. El mismo sistema que contiene la base de datos es el que interactúa con el usuario
Es un modelo que sólo se utiliza con bases de datos pequeñas y poca cantidad de conexiones. El propular software Access de Microsoft es considerada un sistema gestor monocapa (aunque tiene algunas posibilidades para ser utilizado en dos capas).

Ilustración 8. SGBD que usa dos capa (arquitectura cliente/servidor)
Usa un modelo de funcionamiento tipo cliente/servidor. La base de datos y el sistema gestor se alojan en un servidor al cual se conectan los usuarios desde máquinas clientes. Un software de comunicaciones se encarga de permitir el acceso a través de la red. Los clientes deben instalar el software cliente de acceso según las instrucciones de configuración del administrador.
Hay dos posibilidades:
En este caso entre el cliente y el servidor hay al menos una capa intermedia (puede haber varias). Esa capa (o capas) se encarga de recoger las peticiones de los clientes y luego de comunicarse con el servidor (o servidores) de bases de datos para recibir la respuesta y enviarla al cliente.
El caso típico es que la capa intermedia sea un servidor web, que recibe las peticiones a través de aplicaciones web; de este modo para conectarse a la base de datos, el usuario solo requiere un navegador web, que es un software muy habitual en cualquier máquina y por lo tanto no requiere una instalación de software adicional en la máquina cliente.

Ilustración 9. Funcionamiento típico de un SGBD de tres capas
Este modelo es el que más se está potenciando en la actualidad por motivos de seguridad y portabilidad de la base de datos.
Como se ha visto en los apartados anteriores, la base de datos se puede percibir de forma distinta según el tipo de usuario que trabaja con ella.
Hemos visto que los analistas o diseñadores crean un esquema llamado conceptual que es permite modelar la información con la que trabajará la base de datos. Por su parte, los administradores de la base de datos utilizan ese esquema para generar otro esquema llamado interno. Por último los desarrolladores crean los esquemas externos (varios en función de los distintos tipos de usuarios finales que manejarán la base de datos) que facilitará el manejo del sistema.
Los esquemas se realizan utilizando las reglas que definen modelos concretos, la mayoría estandarizados. Así, por ejemplo, es posible crear esquemas conceptuales siguiendo las normas del modelo Entidad/Relación. Pero podríamos crear este tipo de esquemas utilizando otro modelo. Eso ocurre con cada uno de los esquemas que se realizan con la base de datos.
En definitiva, el modelo es la norma concreta de reglas e instrucciones que se utilizan para la creación de un tipo de esquema concreta. Mientras que el esquema es un diseño concreto de la base de datos. Como es lógico, hay modelos conceptuales, externos e internos.
Por lo tanto, cuando se implementa la base de datos en el sistema deberemos primero crear el esquema conceptual (el cual será válido para cualquier SGBD comercial que utilicemos) y después el esquema interno. El último esquema sería el esquema físico que ya indica aspectos relacionados con la implementación concreta en la máquina final.
Sin embargo, entre el esquema conceptual y el interno se suele crear un esquema intermedio conocido como esquema canónico o lógico (en estos apuntes le denominaremos esquema lógico) para adaptar el esquema conceptual a un tipo concreto de SGBD. De hecho, muchas empresas crean el esquema lógico y no el esquema conceptual ya que parten de que saben desde el principio el tipo de SGBD que se utilizará.
Esta práctica es poco recomendable, ya que el esquema conceptual puede reflejar aspectos más avanzados y, además, sigue siendo válido aunque cambiemos de tipo de SGBD en el futuro.
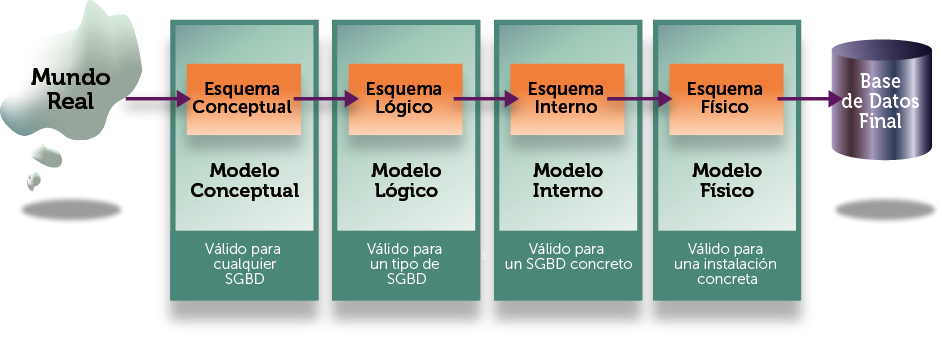
Ilustración 10. Proceso de implementación de una base de datos
Por lo tanto, conocer los distintos tipos de SGBD consiste en conocer los distintos tipos de modelos lógicos
Algunos ejemplos de modelos conceptuales son:
Ejemplos de modelos lógicos son:
A continuación se comentarán los modelos lógicos más importantes.
Era utilizado por los primeros SGBD, desde que IBM lo definió para su IMS (Information Management System, Sistema Administrador de Información) en 1970. Se le llama también modelo en árbol debido a que utiliza una estructura en árbol para organizar los datos.
La información se organiza con un jerarquía en la que la relación entre las entidades de este modelo siempre es del tipo padre / hijo. De esta forma hay una serie de nodos que contendrán atributos y que se relacionarán con nodos hijos de forma que puede haber más de un hijo para el mismo padre (pero un hijo sólo tiene un padre).
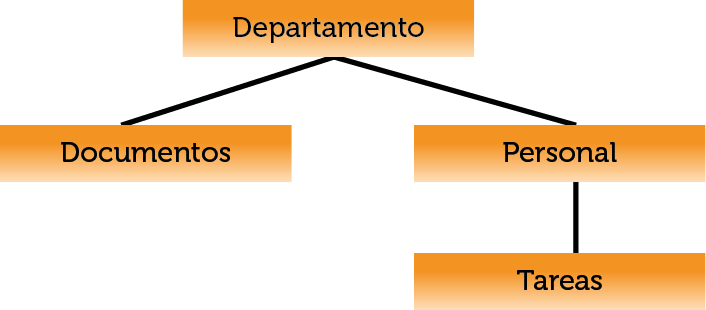
Ilustración 11. Ejemplo de esquema jerárquico
Los datos de este modelo se almacenan en estructuras lógicas llamadas segmentos. Los segmentos se relacionan entre sí utilizando arcos.
La forma visual de este modelo es de árbol invertido, en la parte superior están los padres y en la inferior los hijos.
Este esquema está en absoluto desuso ya que no es válido para modelar la mayoría de problemas de bases de datos. Su virtud era la facilidad de manejo ya que sólo existe un tipo de relación (padre/hijo) entre los datos; su principal desventaja es que no basta para representar la mayoría de relaciones. Además no mantiene la independencia con la física de la base de datos.
No obstante todavía se usa en algunas aplicaciones muy concretas como, por ejemplo, el sistema IMS de IBM (todavía en uso) y el propio registro de Windows.
Es un modelo que tuvo una gran aceptación (aunque apenas se utiliza actualmente). En especial se hizo popular la forma definida por el estándar Codasyl a principios de los 70 que definió un modelo en red muy popular.
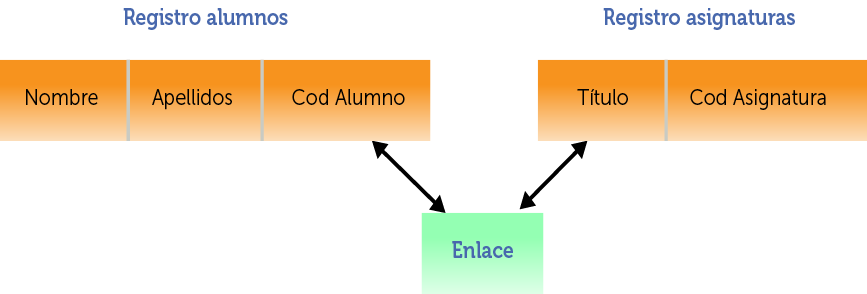
Ilustración 12. Ejemplo de diagrama de estructura de datos Codasyl
El modelo en red organiza la información en registros (también llamados nodos) y enlaces. En los registros se almacenan los datos, mientras que los enlaces permiten relacionar estos datos. Las bases de datos en red son parecidas a las jerárquicas sólo que en ellas puede haber más de un padre.
En este modelo se pueden representar perfectamente cualquier tipo de relación entre los datos (aunque la norma Codasyl restringía las relaciones posibles) lo que le capacitaba para representar todo tipo de bases de datos.
Poseía un lenguaje poderoso de trabajo con la base de datos. El problema era la complejidad para trabajar con este modelo tanto para manipular los datos como programar aplicaciones de acceso a la base de datos. Tampoco mantenía una buena independencia con la física de la base de datos.
Es el modelo más popular todavía en la actualidad. Su modelo se basa en que los datos se organizan en tablas y éstas en columnas y filas de datos. Las tablas se relacionan entre sí para ligar todos los datos.
Se basa en la teoría de conjuntos y consigue una gran separación entre lo conceptual y lo físico, consiguiendo su total independencia. Tiene un lenguaje considerado estándar, el SQL y una enorme red de usuarios y documentación que facilita su aprendizaje. Además dota de una gran facilidad para establecer reglas complejas a los datos.
El problema es que la simplicidad de manejo y la independencia que consigue se logra a base de un software muy complejo que requiere también un hardware poderoso.
Desde la aparición de la programación orientada a objetos (POO u OOP) se empezó a pensar en bases de datos adaptadas a estos lenguajes. La programación orientada a objetos permite cohesionar datos y procedimientos, haciendo que se diseñen estructuras que poseen datos (atributos) en las que se definen los procedimientos (operaciones) que pueden realizar con los datos. En las bases orientadas a objetos se utiliza esta misma idea.
A través de este concepto se intenta que estas bases de datos consigan arreglar las limitaciones de las relacionales. Por ejemplo el problema de la herencia (el hecho de que no se puedan realizar relaciones de herencia entre las tablas), tipos definidos por el usuario, disparadores (triggers) almacenables en la base de datos, soporte multimedia...
Se supone que son las bases de datos de tercera generación (la primera fue las bases de datos en red y la segunda las relacionales), lo que significa que el futuro parece estar a favor de estas bases de datos. Pero siguen sin reemplazar a las relacionales, aunque son el tipo de base de datos que más está creciendo en los últimos años.
Su modelo conceptual se suele diseñar usando la notación UML y el lógico usando ODMG (Object Data Management Group, grupo de administración de objetos de datos), organismo que intenta crear estándares para este modelo.
Sus ventajas están en el hecho de usar la misma notación que la de los programas (lo que facilita la tarea de su aprendizaje a los analistas y desarrolladores) y que el significado de los datos es más completo. Lo malo es que no posee un lenguaje tan poderoso como el modelo relacional para manipular datos y metadatos, que tiene más dificultades para establecer reglas a los datos y que al final es más complejo para manejar los datos.
Tratan de ser un híbrido entre el modelo relacional y el orientado a objetos. El problema de las bases de datos orientadas a objetos es que requieren reinvertir capital y esfuerzos de nuevo para convertir las bases de datos relacionales en bases de datos orientadas a objetos. En las bases de datos objeto relacionales se intenta conseguir una compatibilidad relacional dando la posibilidad de integrar mejoras de la orientación a objetos.
Estas bases de datos se basan en el estándar ISO SQL 2000 y los siguientes. En ese estándar se añade a las bases relacionales la posibilidad de almacenar procedimientos de usuario, triggers, tipos definidos por el usuario, consultas recursivas, bases de datos OLAP, tipos LOB,...
Las últimas versiones de la mayoría de las clásicas grandes bases de datos relacionales (Oracle, SQL Server, DB2, ...) son objeto relacionales.
En los últimos años ha aparecido todo un género de bases de datos (de varios tipos) que intentan paliar deficiencias detectadas en el modelo relacional.
El dominio de este modelo parecía demostrar, durante décadas, que era el tipo ideal de base de datos. El cambio de perspectiva se ha producido por la altísima demanda de servicios que requiere Internet. En especial si lo que se requiere es escribir o modificar datos, ya que actualmente todos los usuarios de Internet crean muchísimos datos cada día que requieren ser almacenados inmediatamente (el caso más claro es el de las redes sociales).
Con este panorama han aparecido nuevos tipos de bases de datos y se han modificado y actualizado tipos antiguos que ahora parecen útiles. Lo que aportan la mayoría de estos tipos de bases de datos, es el uso de otro tipo de esquemas conceptuales e internos más apropiados para este tipo de demandas de usuario.
En resumen las bases de datos NoSQL renuncian al modelo relacional para paliar las carencias del modelo relacional en estos aspectos:
Esto no significa que cada base de datos NoSQL sea capaz de mejorar en todos los aspectos anteriores, cada tipo de base de datos NoSQL está pensado para algunos de los puntos anteriores.
apéndices |
Los ficheros o archivos son la herramienta fundamental de trabajo en una computadora todavía a día de hoy. Las computadoras siguen almacenando la información en ficheros; eso sí, su estructura es cada vez más compleja.
Los datos deben de ser almacenados en componentes de almacenamiento permanente, lo que se conoce como memoria secundaria (discos duros u otras unidades de disco). En esas memorias, los datos se estructuran en archivos (también llamados ficheros).
Un fichero es una secuencia de números binarios que organiza información relacionada a un mismo aspecto.
En general sobre los archivos se pueden realizar las siguientes operaciones:
Los archivos, como herramienta para almacenar información, tomaron la terminología del mundo de la oficina empresarial. Así la palabra dato hace referencia a un valor sea un número o un texto o cualquier otro tipo de datos almacenable.
Cuando podemos distinguir datos referidos a una misma propiedad real a la que podemos poner un nombre, hablamos de campos. Así: Sánchez, Rodríguez, Serrat y Crespo son datos que perfectamente podrían encajar en un campo llamado Primer Apellido.
Los datos que se refieren al mismo elemento real (una persona, una factura, un movimiento bancario,…) se agrupan en registros. En un fichero de datos personales, cada registro sería una persona; cada campo sería cada propiedad distinguible en la persona.
En estos ficheros, los datos se organizan secuencialmente en el orden en el que fueron grabados. Para leer los últimos datos hay que leer los anteriores. Es decir leer el registro número nueve, implica leer previamente los ocho anteriores.
En estos ficheros se puede leer una posición concreta directamente; bastará saber la posición exacta (normalmente en bytes) del dato a leer para obtenerle. Es decir, posicionarnos en el quinto registro se haría de golpe, con una sola instrucción. Lo único que necesitamos saber el tamaño de cada registro, que en este tipo de ficheros debe de ser el mismo. Suponiendo que cada registro ocupa 100 bytes, el quinto registro comenzará en la posición 400. A partir de esa posición podremos leer todos los datos del registro.
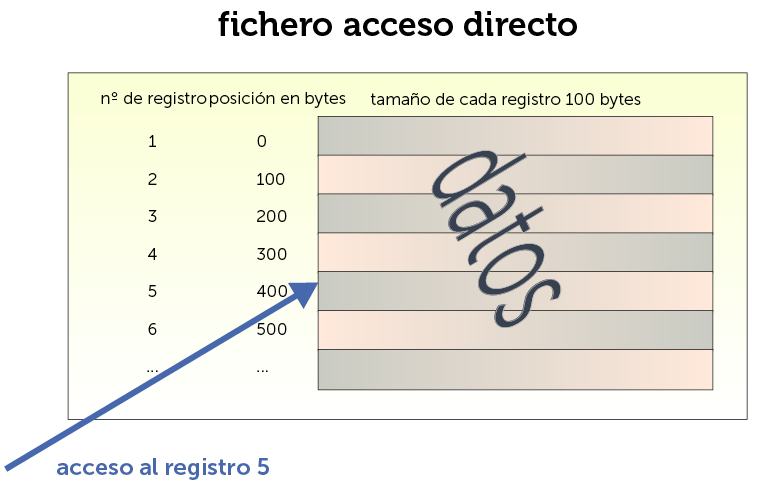
Ilustración 13. Ejemplo de fichero de acceso directo
Son ficheros con registros grabados secuencialmente que podríamos recorrer registro a registro o de forma aleatoria. Además cada registro posee un campo que contiene la dirección de otro registro (a este tipo de campos se les llama punteros). Cada registro usa su puntero para indicar la dirección del siguiente registro. Usando los punteros podremos recorrer los registros en un orden concreto.
Cuando aparece un nuevo registro, se añade al final del archivo, pero los punteros se reordenan para que se mantenga el orden.
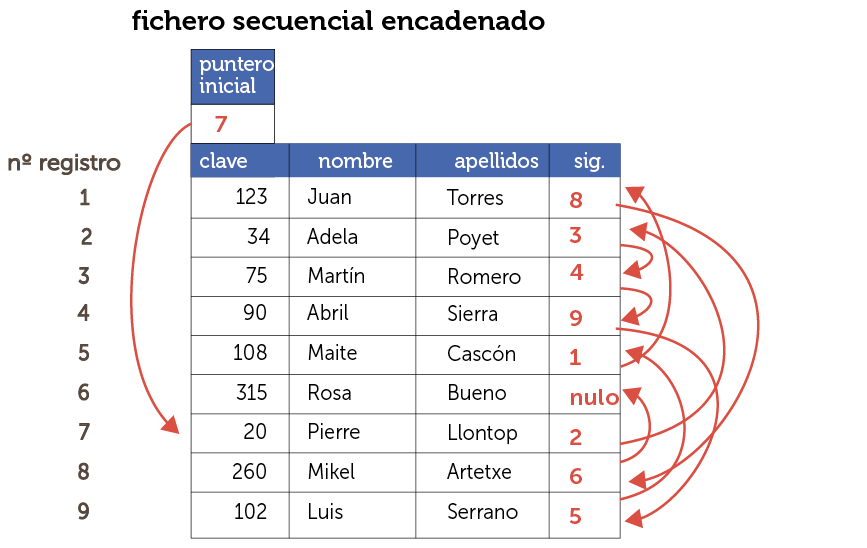
Ilustración 14. Ejemplo de fichero secuencial encadenado. Los punteros le recorren por la clave
Se utilizan dos ficheros para los datos, uno posee los registros almacenados de forma secuencial, pero que permite su acceso aleatorio. El otro posee una tabla con punteros a la posición ordenada de los registros. Ese segundo fichero es el índice, una tabla con la ordenación deseada para los registros y la posición que ocupan en el archivo.
El archivo de índices posee unas cuantas entradas sólo en las que se indica la posición de ciertos valores claves en el archivo (cada 10, 15 ,20,... registros del archivo principal se añade una entrada en el de índices). El archivo principal tiene que estar siempre ordenado y así cuando se busca un registro, se busca su valor clave en la tabla de índices, la cual poseerá la posición del registro buscado. Desde esa posición se busca secuencialmente el registro hasta encontrarlo.
Existe un tercer archivo llamado de desbordamiento u overflow en el que se colocan los nuevos registros que se van añadiendo (para no tener que ordenar el archivo principal cada vez que se añade un nuevo registro) este archivo está desordenado. Se utiliza sólo si se busca un registro y no se encuentra en el archivo principal. En ese caso se recorre todo el archivo de overflow hasta encontrarlo.
Para no tener demasiados archivos en overflow (lo que restaría velocidad ya que no utilizaríamos el archivo de índices que es el que da velocidad), cada cierto tiempo Wse reorganiza el archivo principal, ordenando los datos en el orden correcto y recalculando el archivo de índices. Ejemplo:

Ilustración 15. Ejemplo de fichero secuencial indexado
Utiliza punteros e índices, es una variante encadenada del caso anterior. Hay un fichero de índices equivalente al comentado en el caso anterior y otro fichero de tipo encadenado con punteros a los siguientes registros. La diferencia está en que este segundo fichero que contiene el área primaria de los datos, no está ordenado secuencialmente, sino que el orden se realizaría recorriendo un puntero (como en el caso de los ficheros secuencialmente encadenados).
Cuando se añaden registros se añaden en un tercer fichero llamado de desbordamiento u overflow. En el área de desbordamiento los datos se almacenan secuencialmente, se accede a ellos si se busca un dato y no se encuentra el área primaria.
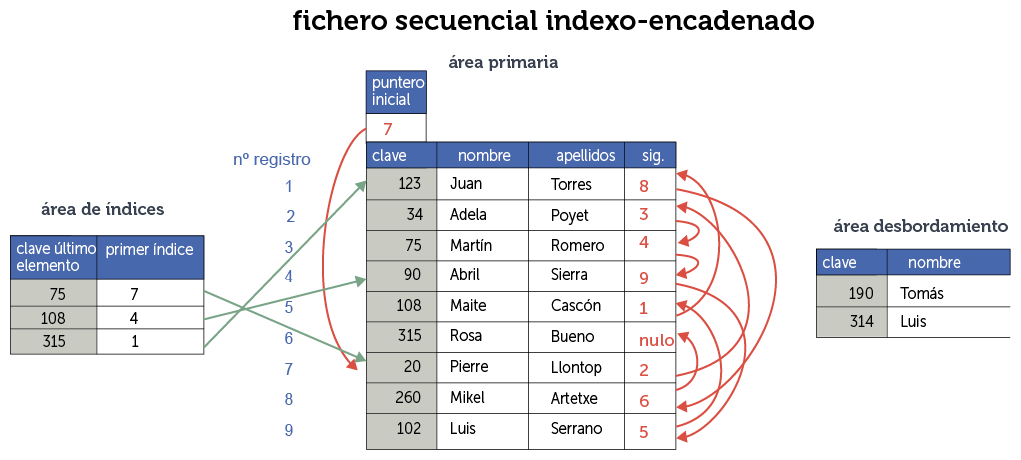
Ilustración 16. Ejemplo fichero secuencial indexado y encadenado
Algunos de los tipos de ficheros vistos anteriormente no admiten el borrado real de datos, sino que sólo permiten añadir un dato que indica si el registro está borrado o no. Esto es interesante ya que permite anular una operación de borrado. Por ello esta técnica de marcar registros, se utiliza casi siempre en todos los tipos de archivos.
En otros casos los datos antes de ser eliminados del todo pasan a un fichero especial (conocido como papelera) en el que se mantienen durante cierto tiempo para su posible recuperación.
La fragmentación en un archivo hace referencia a la posibilidad de que éste tenga huecos interiores debido a borrado de datos u a otras causas. Causa los siguientes problemas:
Por ello se requiere compactar los datos. Esta técnica permite eliminar los huecos interiores a un archivo. Las formas de realizarla son:
En muchos casos para ahorrar espacio de almacenamiento, se utilizan técnicas de compresión de datos. La ventaja es que los datos ocupan menos espacio y la desventaja es que al manipular los datos hay que descomprimirlos lo que hace que las operaciones básicas con el fichero se ralentizan.
Otra de las opciones habituales sobre ficheros de datos es utilizar técnicas de cifrado para proteger los ficheros en caso de que alguien no autorizado se haga con el fichero. Para leer un fichero de datos, haría falta descifrar el fichero. Para descifrar necesitamos una clave o bien aplicar métodos de descifrado; lógicamente cuanto mejor sea la técnica de cifrado, más difícil será descifrar los datos.
Es uno de los aspectos que todavía sigue pendiente. Desde la aparición de los primeros gestores de base de datos se intentó llegar a un acuerdo para que hubiera una estructura común para todos ellos, a fin de que el aprendizaje y manejo de este software fuera más provechoso y eficiente.
El acuerdo nunca se ha conseguido del todo, no hay estándares aceptados del todo. Aunque sí hay unas cuentas propuestas de estándares que sí funcionan como tales.
Los intentos por conseguir una estandarización han estado promovidos por organismos de todo tipo. Algunos son estatales, otros privados y otros promovidos por los propios usuarios. Los tres que han tenido gran relevancia en el campo de las bases de datos son ANSI/SPARC/X3, CODASYL y ODMG (éste sólo para las bases de datos orientadas a objetos). Los organismos grandes (que recogen grandes responsabilidades) dividen sus tareas en comités, y éstos en grupos de trabajo que se encargan de temas concretos.
Entre los trabajos que realiza el grupo WG3 está la normalización de SQL, además de otras normas de estandarización.
Codasyl (COnference on DAta SYstem Languages) es el nombre de una conferencia iniciada en el año 1959 y que dio lugar a un organismo con la idea de conseguir un lenguaje estándar para la mayoría de máquinas informáticas. Participaron organismos privados y públicos del gobierno de Estados Unidos con la finalidad de definir estándares. Su primera tarea fue desarrollar el lenguaje COBOL y otros elementos del análisis, diseño y la programación de ordenadores.
La tarea real de estandarizar esos lenguajes se la cedieron al organismo ANSI, pero las ideas e inicios de muchas tecnologías se idearon en el consorcio Codasyl.
En 1967 se crea un grupo de tareas para bases de datos (Data Base Task Group) y este grupo definió el modelo en red de bases de datos y su integración con COBOL. A este modelo en red se le denomina modelo Codasyl o modelo DBTG y fue finalmente aceptado por la ANSI.
ANSI (American National Standards Institute) es un organismo científico de Estados Unidos que ha definido diversos estándares en el campo de las bases de datos. X3 es la parte de ANSI encargada de los estándares en el mundo de la electrónica. Finalmente SPARC, System Planning and Repairments Committee, comité de planificación de sistemas y reparaciones es una subsección de X3 encargada de los estándares en Sistemas Informáticos en especial del campo de las bases de datos. Su logro fundamental ha sido definir un modelo de referencia para las bases de datos (que se estudiará posteriormente).
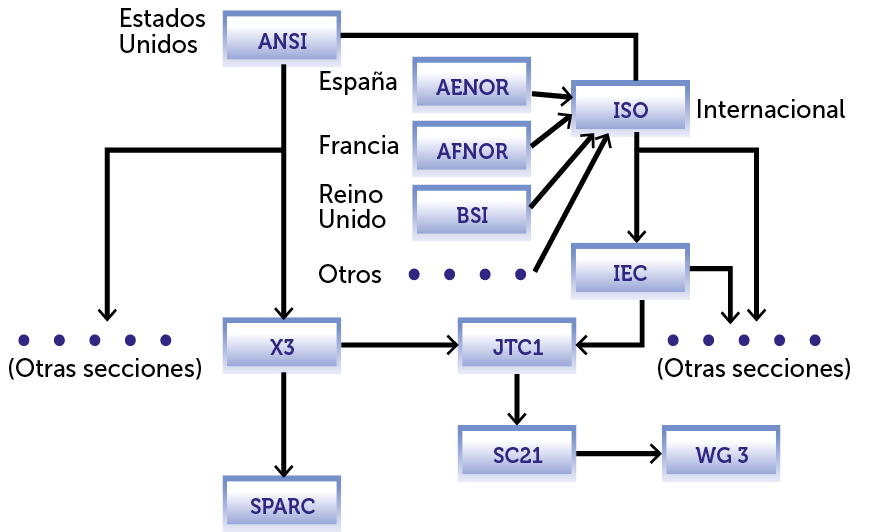
Ilustración 17. Relación entre los organismos de estandarización
En la actualidad ANSI para Estados Unidos e ISO para todo el mundo son nombres equivalentes en cuanto a estandarización de bases de datos, puesto que se habla ya de un único modelo de sistema de bases de datos.
El organismo ANSI ha marcado la referencia para la construcción de SGBD. El modelo definido por el grupo de trabajo SPARC se basa en estudios anteriores en los que se definían tres niveles de abstracción necesarios para gestionar una base de datos. ANSI profundiza más en esta idea y define cómo debe ser el proceso de creación y utilización de estos niveles.
En el modelo ANSI se indica que hay tres modelos: externo, conceptual e interno. Se entiende por modelo, el conjunto de normas que permiten crear esquemas (diseños de la base de datos).
Los esquemas externos reflejan la información preparada para el usuario final, el esquema conceptual refleja los datos y relaciones de la base de datos y el esquema interno la preparación de los datos para ser almacenados.
El esquema conceptual contiene la información lógica de la base de datos. Su estructuración y las relaciones que hay entre los datos.
El esquema interno contiene información sobre cómo están almacenados los datos en disco. Es el esquema más cercano a la organización real de los datos.
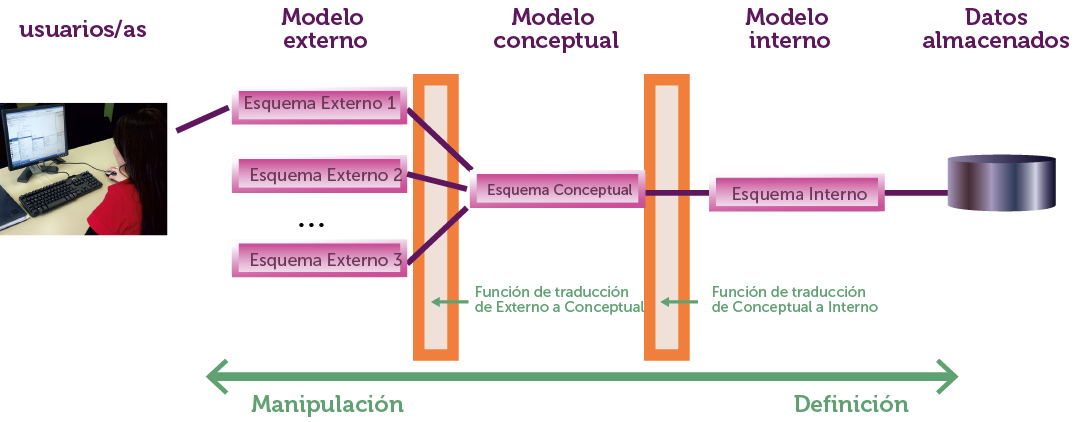
Ilustración 18. Niveles en el modelo ANSI
En definitiva el modelo ANSI es una propuesta teórica sobre cómo debe de funcionar un sistema gestor de bases de datos (sin duda, la propuesta más importante). Su idea es la siguiente:
En la Ilustración 18, el paso de un esquema a otro se realiza utilizando una interfaz o función de traducción. En su modelo, la ANSI no indica cómo se debe realizar esta función, sólo que debe existir.
La arquitectura completa (Ilustración 19) está dividida en dos secciones, la zona de definición de datos y la de manipulación. Esa arquitectura muestra las funciones realizadas por humanos y las realizadas por programas.
En la fase de definición, una serie de interfaces permiten la creación de los metadatos que se convierten en el eje de esta arquitectura. La creación de la base de datos comienza con la elaboración del esquema conceptual realizándola el administrador de la empresa (actualmente es el diseñador, pero ANSI no lo llamó así). Ese esquema se procesa utilizando un procesador del esquema conceptual (normalmente una herramienta CASE, interfaz 1 del dibujo anterior) que lo convierte en los metadatos (interfaz 2).
La interfaz 3 permite mostrar los datos del esquema conceptual a los otros dos administradores: el administrador de la base de datos y el de aplicaciones (el desarrollador). Mediante esta información construyen los esquemas internos y externos mediante las interfaces 4 y 5 respectivamente, los procesadores de estos esquemas almacenan la información correspondiente a estos esquemas en los metadatos (interfaces 6 y 7).
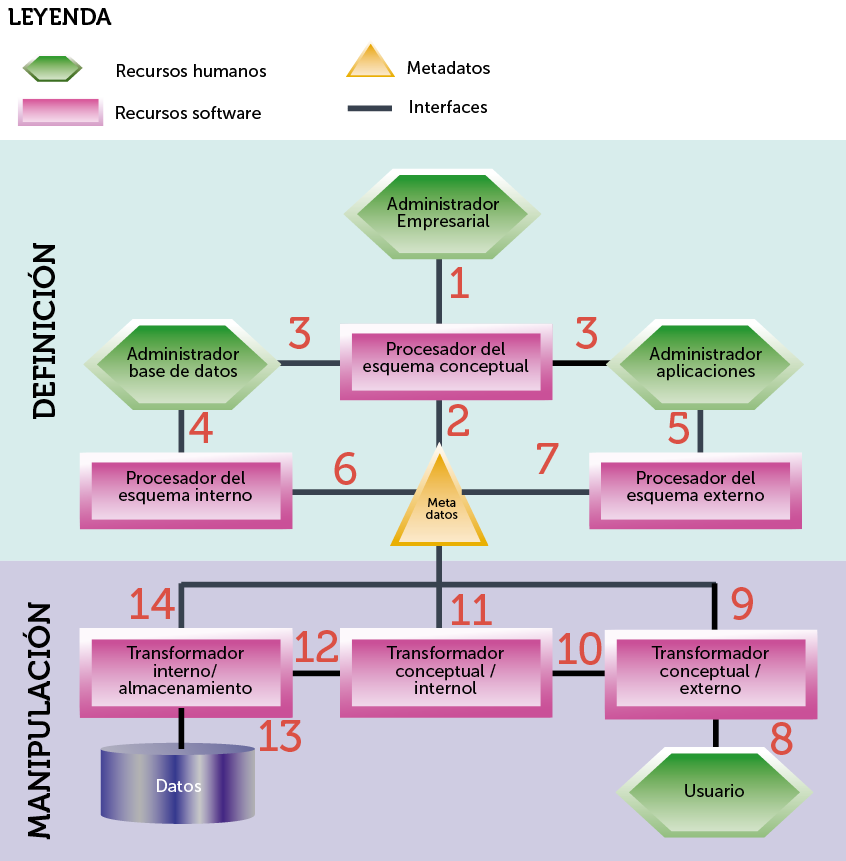
Ilustración 19. Arquitectura ANSI, explicación clásica del funcionamiento de un Sistema Gestor de Bases de Datos incluyendo los recursos humanos implicados
En la fase de manipulación el usuario puede realizar operaciones sobre la base de datos usando la interfaz 8 (normalmente una aplicación) esta petición es transformada por el transformador externo/conceptual que obtiene el esquema correspondiente ayudándose también de los metadatos (interfaz 9). El resultado lo convierte otro transformador en el esquema interno (interfaz 10) usando también la información de los metadatos (interfaz 11). Finalmente del esquema interno se pasa a los datos usando el último transformador (interfaz 12) que también accede a los metadatos (interfaz 13) y de ahí se accede a los datos (interfaz 14). Para que los datos se devuelvan al usuario en formato adecuado para él se tiene que hacer el proceso contrario (observar dibujo).